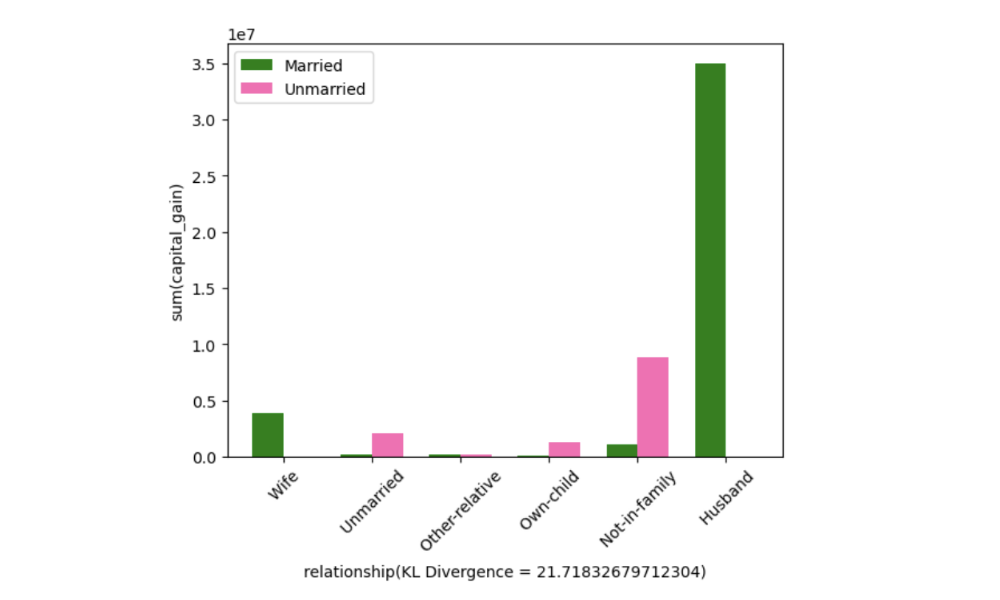
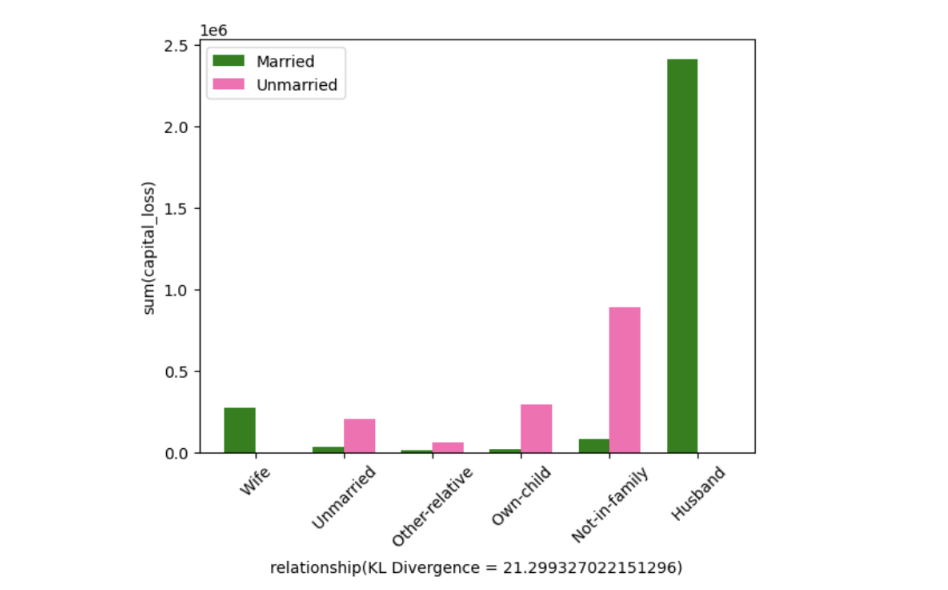
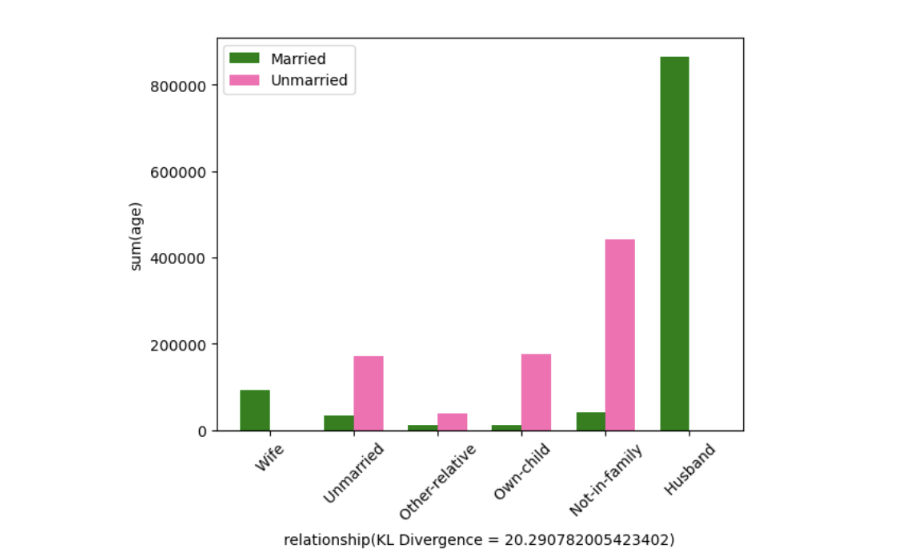
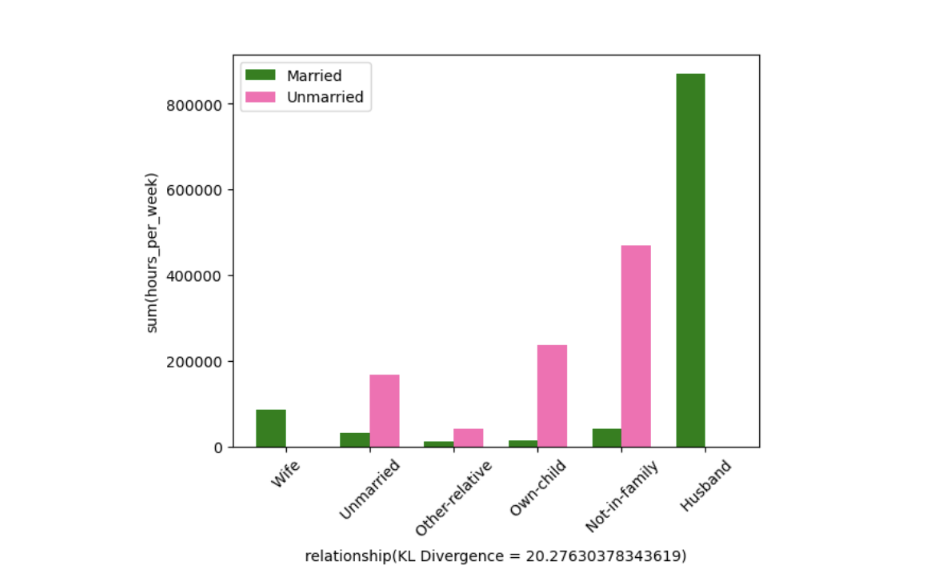
- Developed and optimized SeeDB, a data-driven visualization recommendation engine that suggests “interesting” visualizations to support rapid data analysis.
- Implemented sharing-based and pruning-based techniques to improve performance, cutting query execution time from 24.9 seconds to 2.07 seconds.
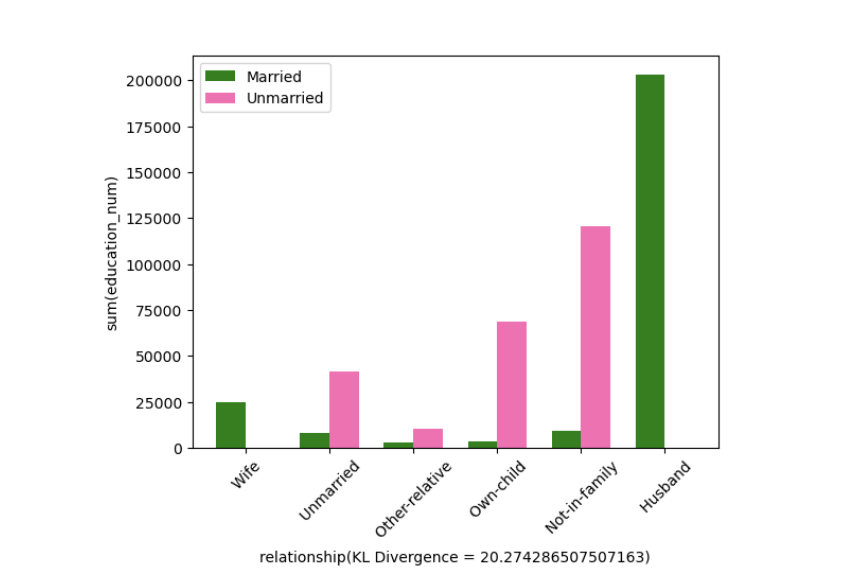
- Used Kullback-Leibler divergence as a utility metric to rank visualizations based on their informational value, enabling faster identification of high-value insights.
- Streamlined database queries by combining group-by operations with PostgreSQL’s Grouping Sets to handle multiple aggregates in a single operation, enhancing scalability.
- Integrated a confidence interval-based pruning approach to filter out low-value visualizations, reducing computational load while maintaining recommendation quality.
- The graphs above are the top 5 most interesting visualizations.
- Reference Paper: https://www.vldb.org/pvldb/vol8/p2182-vartak.pdf
Project information
- Technologies PostgreSQL, Matplotlib, SciPy
- Languages ython, SQL
- Visit Code